
A Estatística e os Dados: decifrando o diálogo
Quando eu entrei no curso de Estatística, uma das primeiras cadeiras que realizei como calouro era chamada de Estatística Descritiva. Com o tempo, aprendendo mais sobre a área de dados, entendi que aquela simples cadeira estava, na verdade, me ensinando o funcionamento do nosso mundo. Como? Apenas explicando o conceito de Estatística (como ciência) e suas áreas. Mas calma meu povo e minha pova; vamos por partes!
A Estatística como Ciência
- Coleta de Dados;
- Organização de Dados;
- Análise de Dados;
- Interpretação de Dados.
A Estatística como Ciência compreende todos esses itens acima, pois ela é rica em ferramentas que auxiliam na tomada de decisões. Graças a isso, ela é de grande utilidade para as mais diversas áreas do conhecimento - engenharia, computação, física, química -, bem como setores do mercado - saúde, finanças, indústria, educação, tecnologia.
Estatística Descritiva
O foco dessa área, como o próprio nome já diz, é descrever dados (associados a contagens, gráficos) e extrair a informação de interesse. Muito do que aprendi do objetivo do Business Intellingence é uma evolução ou adaptação empresarial do objetivo da estatística descritiva. Vamos ilustrar com um exemplo:
Exemplo: Considere uma empresa que venda um determinado produto. Ela contém 2 vendedores. Gostaríamos de saber quantas vendas cada um realizou ao longo do ano, bem como a venda média mensal de cada um.
Inicialmente, para resolvermos este problema, precisamos registrar quantas vendas cada um realizou ao longo do período (Coleta de Dados). Após isso, Organizar os Dados (tabulando, por exemplo) para que possa ser feita a extração de informações.
| mes | vendedor | vendas |
|---|---|---|
| 1 | A | 5 |
| 2 | A | 3 |
| 3 | A | 2 |
| 4 | A | 14 |
| 5 | A | 20 |
| 6 | A | 4 |
| 7 | A | 6 |
| 8 | A | 1 |
| 9 | A | 2 |
| 10 | A | 1 |
| 11 | A | 5 |
| 12 | A | 3 |
| 1 | B | 1 |
| 2 | B | 5 |
| 3 | B | 7 |
| 4 | B | 9 |
| 5 | B | 4 |
| 6 | B | 3 |
| 7 | B | 5 |
| 8 | B | 6 |
| 9 | B | 8 |
| 10 | B | 5 |
| 11 | B | 2 |
| 12 | B | 1 |
Após isso, podemos facilitar a visualização por meio de gráficos, bem como calcular algumas medidas para respondermos nossa pergunta.
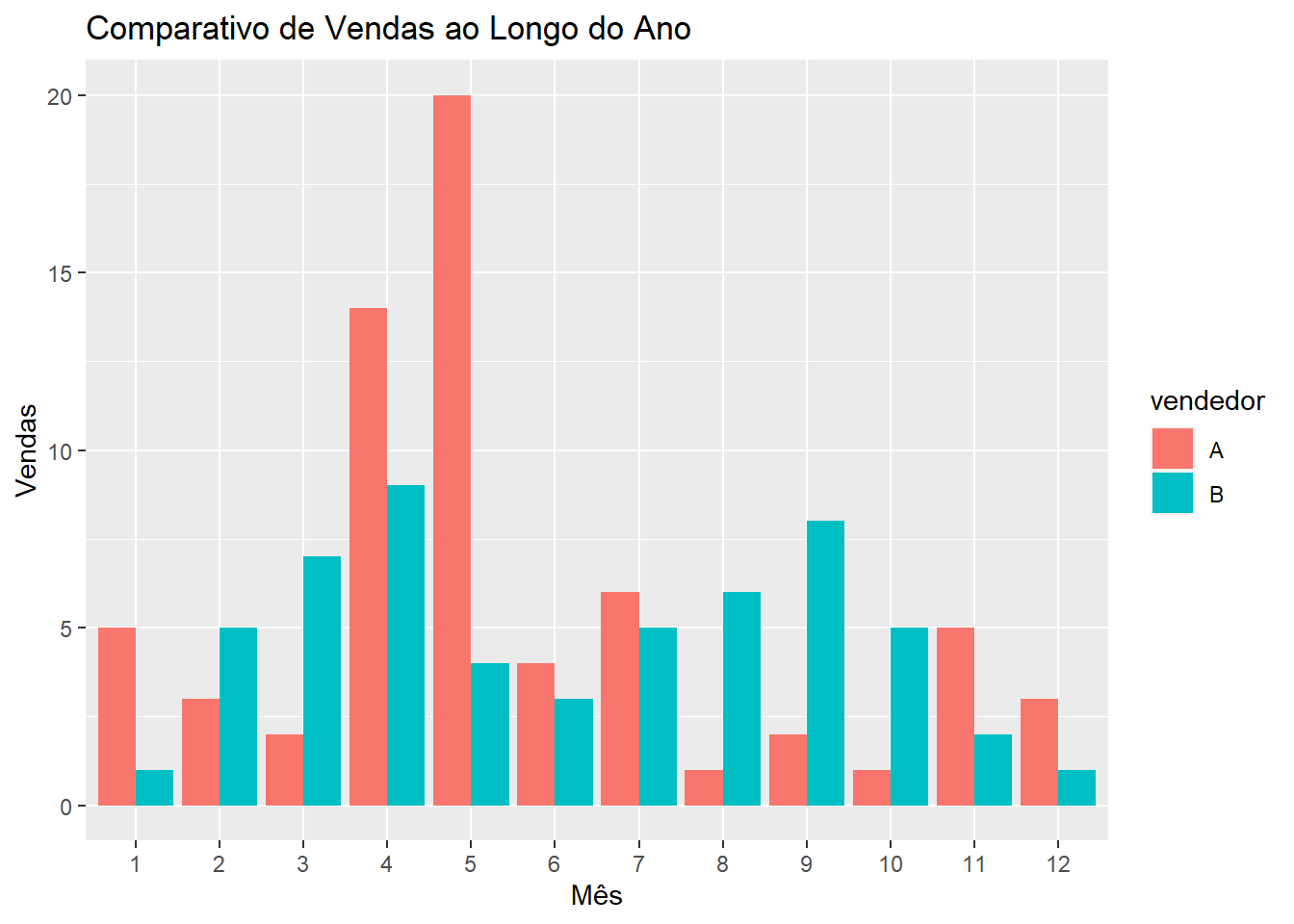
Pode-se observar, pelo gráfico acima, que o vendedor A realizou mais vendas no mês 5 (maio) do que o vendedor B, assim como o vendedor B vendeu mais no mês 9 (setembro) do que o vendedor A. Para facilitar a comparação, realizaremos o cálculo da média anual de vendas para identificar quem vendeu mais (em média).
| vendedor | media |
|---|---|
| A | 5.50 |
| B | 4.67 |
Com base na tabela acima e nos dados, temos que, em média, o vendedor A vende 5.50 unidades e o vendedor B 4.67 unidades por mês. Ou seja, o vendedor A vende cerca de uma unidade a mais do que o vendedor B (em média).
Estatística Inferencial
Alguma vez você já ouviu alguma notícia ou leu uma manchete que dizia algo como “95% das pessoas acreditam que comer faz bem” e pensou: “Ué, mas não perguntaram isso para mim.” ? Pois é, este é o objetivo dessa área da Estatística - obter conclusões sobre um todo (população) com base nos dados de uma parcela menor desse todo (amostra). Você pode pensar: mas isso funciona? SIM! Quando você (amigo, familiar) cozinha uma sopa, é normal experimentar um pouco para averiguar, por exemplo, se está salgada ou não. Esse pouco nada mais é do que uma amostra da tua sopa, e com ela pode-se concluir se a sopa está salgada ou não. Claro que temos incerteza envolvida; o processo de indução não é exato. No entanto, podemos calcular até quanto estamos errando por meio da Teoria de Probabilidades. Vou ilustrar com um exemplo.
Considere que em uma sala há 500 tigelas cheias de sopas. Em 250 delas (50%), a sopa está salgada. Sorteareamos, de forma aleatória, 50 sopas (10%) para distribuir para nossos convidados e eles nos informarão se a sopa está salgada ou não. Será que dessas 50 sopas, teremos cerca de 25 (metade de 50) salgadas?
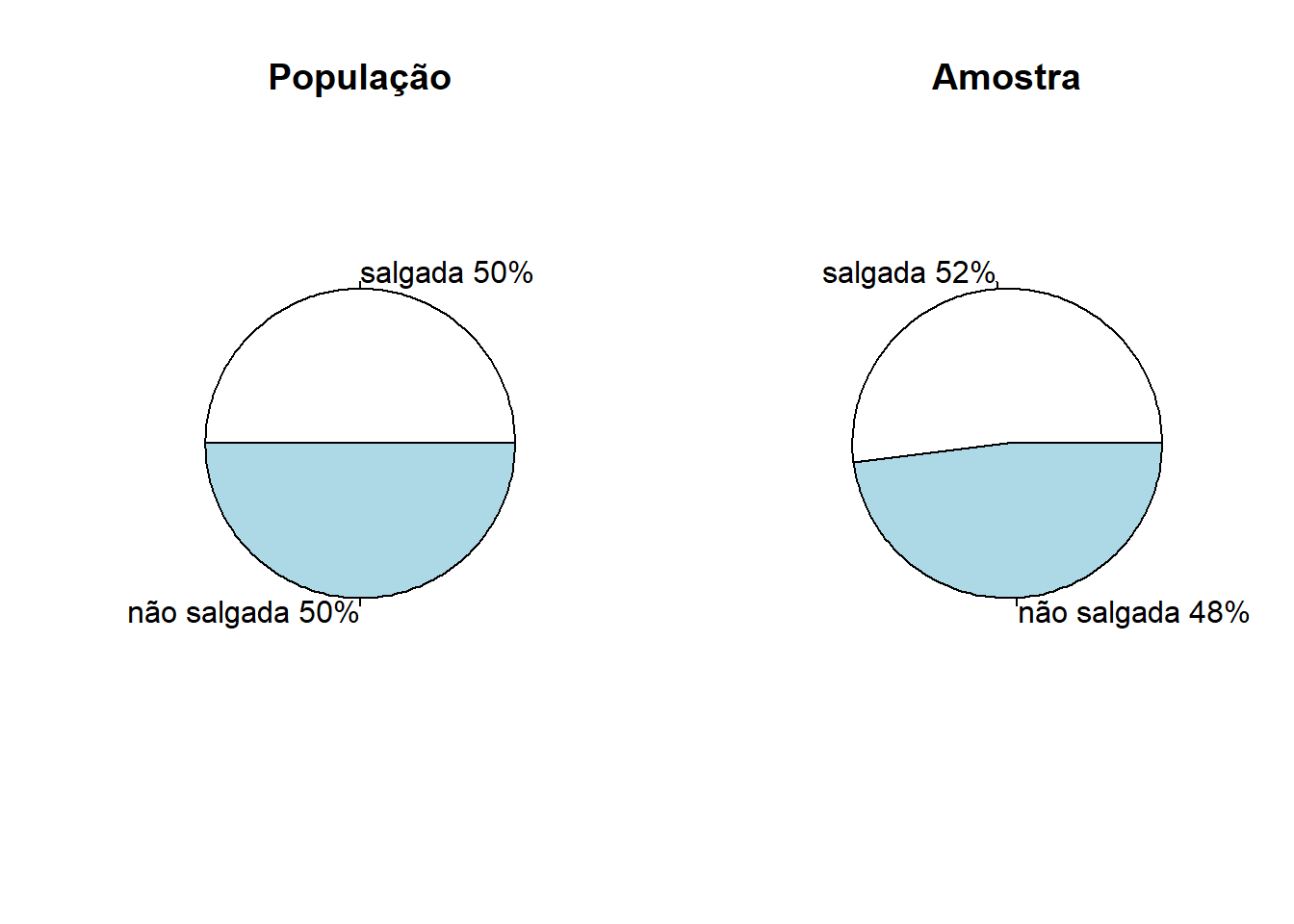
Como podemos notar nos gráficos acima, nossa amostra errou um pouco a proporção de sopas salgadas e não salgadas. No entanto, podemos notar que o erro foi de apenas 2% (cima e baixo). Claro que existirão casos com diferentes erros (alguns mais extremos do que outros), mas minha ideia foi mostrar que mesmo não sendo exato, podemos obter uma aproximação boa por meio da amostra. Utilizando a teoria de probabilidades, podemos calcular até que ponto nossas induções estão erradas.
Àqueles que chegaram até aqui, agradeço a atenção. Quaisquer dúvidas, sugestões e críticas que tiverem, por favor deixem nos comentários. Vou adorar o feedback!
